
Anyone watching streaming television is no stranger to the ‘Recommended For You’ category. Just like clockwork, every time you finish a series or movie on an on-demand service, you will be prompted with multiple new things to watch based on their similarity to what you’ve just consumed. Most music streaming platforms have a “radio” or “playlist” feature where similar songs or artists are grouped to play together for your convenience. These recommendation systems, based on data similarities between items, are everywhere now, and they are incredibly effective in keeping users endlessly engaged.
But these recommendations have limitations. If the products are not something you would want multiples of, then the list of items isn’t useful. In commerce (both online and brick-and-mortar), a shopper is unlikely to want more than one of certain consumable products at a time. Consumers generally only buy one type of shampoo at a time, so a campaign recommending another brand of shampoo isn’t likely to be successful. A campaign that serves up recommendations for a conditioner or face wash from the same brand is far more likely to increase the amount of revenue and satisfaction you will generate with the same customer base. You’ve probably come across these complementary recommendations on your last grocery trip: red solo cups being sold in the same aisle as beer, can openers in the same aisle as canned beans, pita chips right next to the hummus instead of being in the chips aisle, etc.
These groups of items which frequently occur together in a given dataset are known as a frequent itemset. Association rules are what is used to identify relationships between different items in a frequent itemset- the likelihood of a customer also buying product A if they are buying product B. This is incredibly useful when cross-selling as one can leverage historical patterns in data to form their strategy with related or complementary products. The alternative to getting these kinds of insights in a marketing or sales tool is to manually identify these products and relationships, a slow and expensive process.
The following is Revio’s strategy for how we have applied these concepts to a cross-selling recommendation system for our community bank customers:
What are Frequent Itemset and Association Rules?
Frequent Itemset and Association Rule mining is a data mining technique used to identify relationships between sets of items, frequent itemsets, and sets of conditions, association rules. It is an unsupervised learning method which means it doesn’t rely on pre-existing labels or classes. Frequent itemset mining is the process of discovering combinations of items from a transaction dataset. These frequent itemsets are then used to identify association rules, which are if-then statements that describe relationships between items. If a customer consistently buys bread and milk, then it is likely they will buy butter. This makes the bread and milk a frequent itemset, and the rule to group bread and milk is an association rule.
In the context of banking products, an association rule would be: if a customer has a business checking account for a certain period of time and exceeds a certain deposit balance threshold, then they are likely interested in a business savings account or CD to earn yield on their cash reserve.
By building recommendations based on past successful cross-sells (customers with existing multiple bank products with your institution), we can generate insights based on your specific customer relationships and the unique products and services that your institution offers.
Data Collection and Preparation
The relevant data includes information about the customers, their banking history, and the products they already have. Product data may include type of account (checking, savings, money market, etc.) and type of customer (individual or business). Banking history data may include information such as account type, transaction frequency, transaction amounts, etc. This data can be collected from various sources, such as transactional databases and customer relationship management systems. We enrich transactional data with information about their purpose and the third-parties involved by parsing transaction descriptions and relevant metadata such as method of payment, amount, and cadence of recurring transactions.
Frequent Itemsets Aggregation and Association Rules Generation
We leverage the FP-Growth algorithm to find frequent itemsets of banking products in our customers’ data. First, we build a tree-like structure called an FP-Tree (Frequent Pattern Tree), which represents the itemsets in the data. Each node of the FP-Tree represents an item, and the itemsets are sorted in descending order of frequency.
To build the FP-Tree, we scan the dataset once and count the frequency of each item, then we sort the items in descending order of frequency. This step reduces the complexity of the algorithm and speeds up the training process. Next, we scan the dataset again, but this time for each customer we order the items based on their frequency. The items are inserted into the FP-Tree one by one starting from the most frequent. If a branch for an item already exists, we extend that branch; otherwise, we create a new branch.
Once the FP-Tree is built, we ‘mine’ it for frequent itemsets by traversing the paths of the tree. We start with the least frequent item and follow its branch in the FP-Tree. Then, we find all the combinations of this item with the other items in the branch. These combinations form the frequent itemsets. This process is repeated recursively for each branch and item in the FP-Tree until we have all the frequent itemsets. By using the FP-Growth algorithm, we can efficiently find frequent itemsets in a large dataset without having to generate all possible combinations.
Once the frequent itemsets have been generated, the next step is to generate association rules from them. This involves identifying relationships between different products in the frequent itemsets. An association rule is a description of the relationship between the antecedent (i.e. the existing product) and the consequent (i.e. the potential product recommendation).
A common metric used to evaluate association rules is the support-confidence-lift framework:
- The support of a rule is the number of transactions that contain both the antecedent and the consequent of the rule divided by the total number of transactions.
- The confidence of a rule is the fraction of transactions that contain the consequent of the rule given that they contain the antecedent of the rule.
- The lift of a rule is the ratio of the support of the rule to the expected support of the rule if the antecedent and consequent were independent.
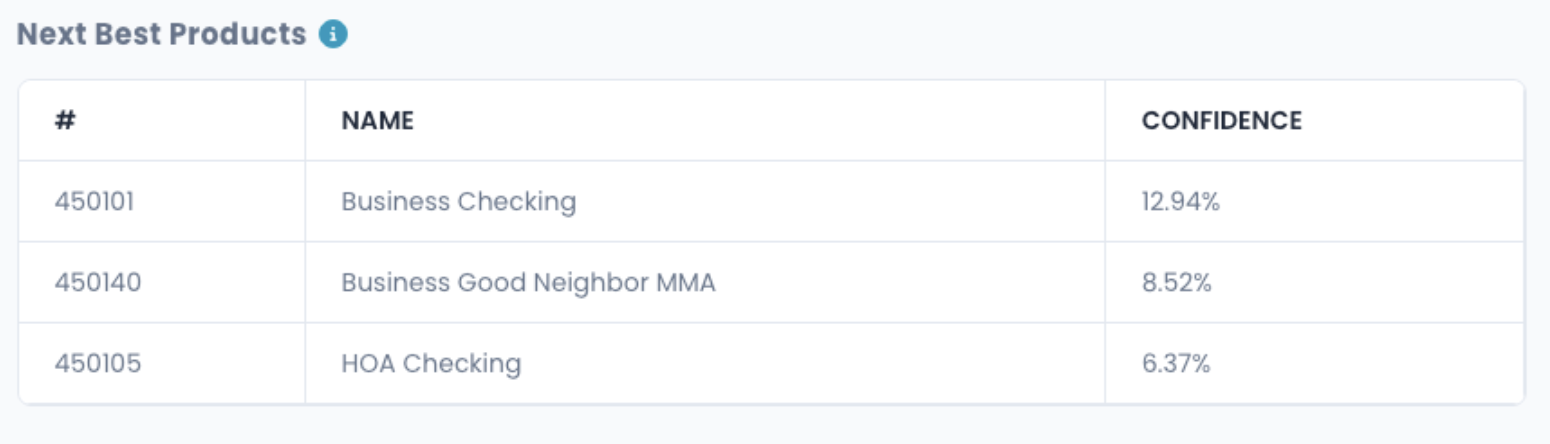
We generate recommendations on existing product(s) for each customer based on these metrics, and then sort those recommendations by how strong the association rule is.
One implementation of this recommendation system might follow a content-based filtering approach. It only takes into account the banking products a customer already has and the relationships between those and other products your financial institution offers as described by the association rules. However, we can also utilize a hybrid approach and consider the similarities between customers (collaborative filtering) in addition to the association rules, such as similar spending patterns, geographical locations, cash deposit amounts, etc. This allows us to discover deeper insights with greater accuracy and only deliver the most useful recommendations.
Conclusion
At a community bank, your existing customer relationships are very important, and appropriate data-driven insights into those relationships are crucial in helping both you and your customers grow. At Revio, we get you plugged in to see the full picture of your existing customer base and leverage that knowledge to expand the products and services you can offer. We hope to be transparent about our process, strategy, and methods to help push the entire industry forward because we believe that when community banks thrive, communities thrive.

